Connecting to a database from Python seems simple enough - you create a client, send queries, and handle results. But when we scaled that to thousands of concurrent requests under an async web server, things got a bit more interesting.
This post walks through how we hit a classic concurrency issue in our ClickHouse integration - how it appeared, what caused it, the quick fix we applied, and finally how we designed a long-term scalable solution using an async connection pool.
The Setup
Our backend service is a data ingestion API that pushes concurrent large JSON payloads into ClickHouse. It runs on top of Uvicorn, an ASGI web server that handles requests asynchronously.
We used the official clickhouse-connect library to communicate with the database. In the beginning, the design looked clean and simple:
# Simplified version of the initial design
class CB:
def __init__(self):
self.client = AsyncClient(
host="clickhouse_host",
port=8123,
database="DB_NAME",
username="default",
password="default"
)
async def post_raw(self, payload):
await self.client.insert(table="m_data", data=payload)
We created a single AsyncClient instance when the backend started - a singleton pattern. Every request reused this same client to perform queries, inserts and health checks.
We leveraged ClickHouse's server-side asynchronous insert feature by configuring the insertion settings to use async_insert=1. This setting is key for high-throughput ingestion, as it tells the ClickHouse server to buffer and batch data internally. However, as we soon discovered, server-side data handling being asynchronous does not guarantee client-side session safety.
The Problem Appears
Everything was smooth in development and staging environments. It looked fine - until we hit production and started ingesting thousands of rows per minute, the logs exploded with the following message:
Attempt to execute concurrent queries within the same session. Please use a separate client instance per thread/process.
Thirty percent of the inserts began failing randomly under load. Some succeeded, others didn't. It wasn't deterministic - but it was bad.
The Role of Uvicorn and Async Concurrency
Our API application runs on Uvicorn web server, which means requests are handled asynchronously on a single event loop by the uvloop library.
In async Python, multiple coroutines (i.e., concurrent requests) share the same event loop and can all run at once when waiting on I/O. So even though we weren't using multiple OS threads (no parallelism), we achieved high concurrency within the same single-threaded process by efficiently switching between waiting requests.
Here's what was happening under the hood:
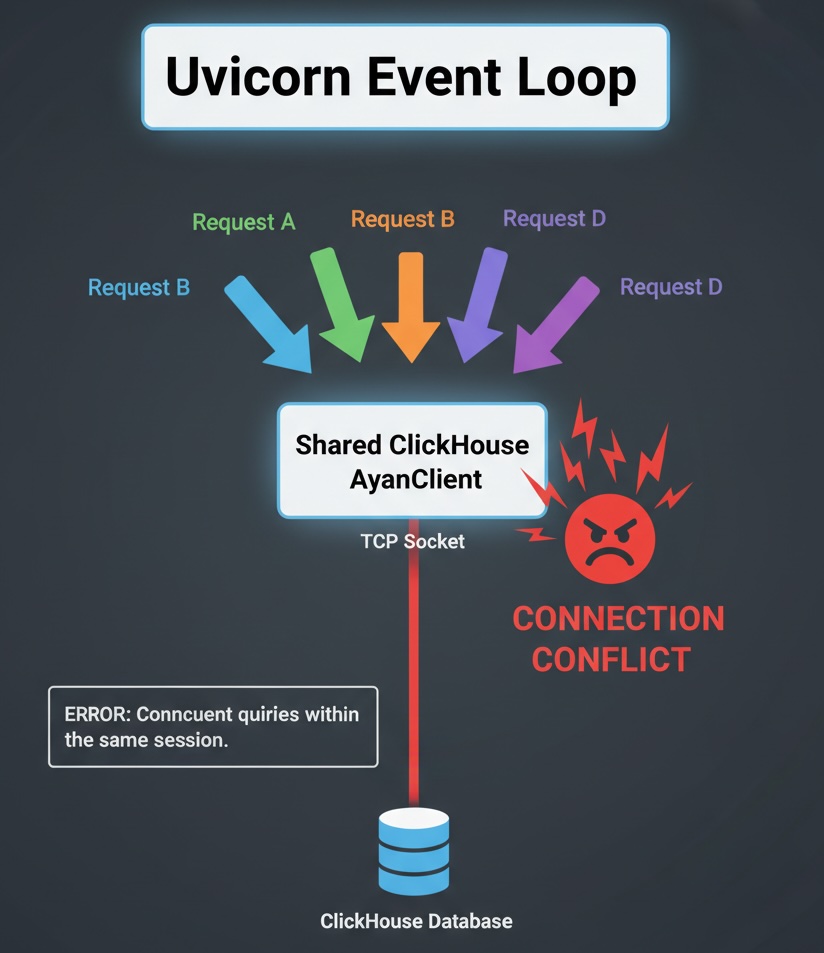
Because all requests used the same Clickhouse AsyncClient instance, multiple coroutines tried to send different queries over the same underlying TCP session - at the same time. This scenario is a classic example of shared mutable state in an asynchronous environment. Multiple requests raced to use the same underlying socket before the previous query had finished, violating the database client's contract.
ClickHouse rightfully rejected this pattern. Its client session protocol doesn't support multiple concurrent queries per connection. Each query must complete before another begins on the same connection.
It's important to distinguish between ClickHouse's server-side asynchronous insert feature (async_insert=1) and our client-side asynchronous concurrency (Uvicorn/coroutine model). The server-side feature efficiently buffers the data. However, the client driver still requires a non-conflicting network session to send the insert request and receive the response (even if that response is a quick acknowledgement). Our problem was that multiple coroutines were attempting to initiate their separate insert operations over the single shared client session at the exact same moment, which the client/session protocol disallowed. The fix was necessary to resolve the session-level concurrency issue, not the server's data-buffering mechanism.
That's why the error message said:
Please use a separate client instance per thread/process.
Even though we weren't using multiple threads, we had the same effect: concurrent use of a shared connection.
Quick Fix: One Client per Request
When production fire alarms are ringing, elegance comes second.
As a quick fix, we changed our approach to create a new ClickHouse client per request.
async def post_data(self, payload):
async with AsyncClient(client=get_client(...)) as client:
await client.insert(...)
That immediately solved the concurrency issue. Each request had its own isolated client - and therefore its own TCP session - avoiding shared-state problems completely.
But this (and probably most) quick solution came at a cost.
Creating and closing a ClickHouse client for every single request is expensive. At large ingestion volumes, it increases connection setup overhead, authentication latency, and CPU churn on both the client and server sides.
We needed something more efficient.
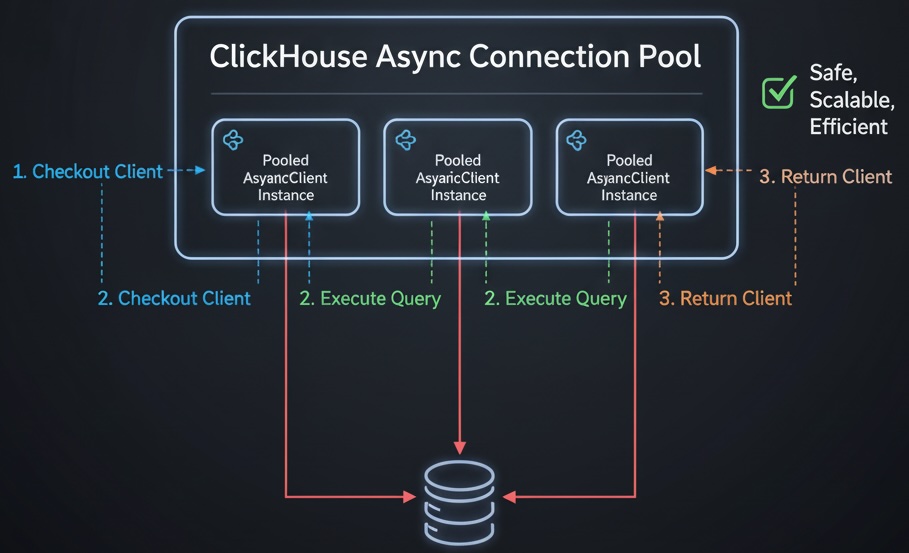
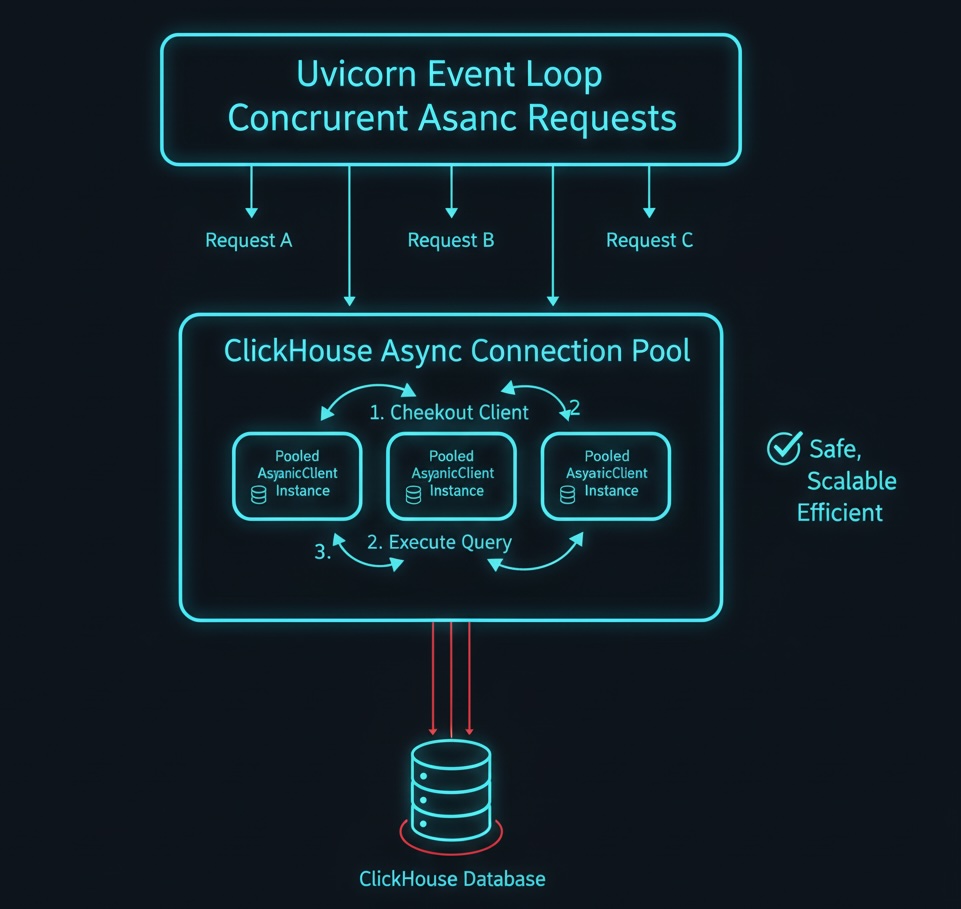
The Final Fix: Connection Pooling
Once stability returned, we revisited the design.
Instead of one global client or one-per-request, we moved to a connection pool - maintaining a fixed number of ready-to-use ClickHouse clients and reusing them efficiently.
New approach
class PooledClient:
"""Helper Context Manager Class"""
def __init__(self, pool, client):
self._pool = pool
self.client = client
async def __aenter__(self):
"""Called when 'async with' starts"""
return self.client
async def __aexit__(self, exc_type, exc_val, exc_tb):
"""
Called when 'async with' block ends (even on error).
For simplicity, we just return the client to the pool.
(You could add logic here to replace broken clients.)
"""
if not getattr(self.client, "is_closed", False):
await self._pool.put(self.client)
return False
class ClickhousePool:
"""Main Connection Pool Class"""
def __init__(self):
self._pool = asyncio.Queue(maxsize=SIZE)
for _ in range(SIZE):
client = AsyncClient(client=get_client(...))
self._pool.put_nowait(client)
async def get_client(self):
"""Returns a context manager object that handles the client lifecycle"""
return PooledClient(self._pool, await self._pool.get())
async def post_data(self, payload):
"""The Clean Consumption in the API"""
rows = ... # transformations of payload
table_name = ...
columns = ...
async with self.get_client() as client:
await client.insert(
table=table_name,
data=rows,
column_names=columns,
settings={
'async_insert': 1,
'wait_for_async_insert': 0,
# ... other settings
}
)
Once the connection pool is in place, usage of async API is straightforward:
cp = ClickhousePool() await cp.post_data(payload)
With the pooled design we make sure that, (1) each of the requests borrow a client from the pool, (2) they use it to execute a query or insert, (3) the client is released back into the pool afterward, (4) if a client breaks (due to a network or protocol error), it's replaced with a new one.
This hybrid approach provides safety by not sharing clients across concurrent requests, performance by avoiding recreate clients repeatedly, scalability by easily tune pool size to match workload.
Singleton -> One global AsyncClient
Per-request -> New client per request
Connection pool -> Limited shared pool, reused safely
Validation and Results
Once deployed, the difference was clear.
We validated the new behavior in three ways. Error messages related to concurrent queries within the same session disappeared completely. Connection metrics stabilized - fewer reconnections, more consistent query latencies. The ClickHouse row count graphs started growing linearly again - confirming ingestion pipelines were back to full capacity.
Lessons Learned
One of the key takeaways from this experience was realizing that asynchronous code isn't automatically thread-safe or concurrency-safe. Using async functions doesn't guarantee that shared resources can be accessed safely by multiple coroutines. In our case, reusing a single AsyncClient across concurrent requests seemed fine at first, but when multiple coroutines tried to use it simultaneously, it led to unexpected failures. The event loop can rapidly switch between these coroutines, and if the underlying resource isn't designed for concurrent access, it will eventually break - exactly as we saw with the ClickHouse client.
We also learned that Uvicorn's speed comes from concurrency, not parallelism. It multiplexes many requests on a single event loop in one process. That means even though the server feels lightweight and fast, all those requests are sharing the same runtime environment. Any global object - such as a database connection, HTTP session, or cache client - must be carefully managed to ensure it's concurrency-safe. The illusion of simplicity in async code can be deceptive; behind the scenes, coroutines are continuously yielding and resuming, which magnifies issues caused by shared mutable state.
When production problems strike, it's often tempting to apply quick fixes to restore stability. We did the same by creating one client per request - a brute-force but effective short-term solution. It isolated each operation and immediately eliminated concurrency conflicts. However, that approach didn't scale well. Each new client meant an additional connection handshake, authentication cycle, and network setup overhead. It worked to stop the bleeding, but it wasn't efficient enough for a high-throughput ingestion system. A connection pool, on the other hand, gave us the right balance - isolation without excessive overhead.
Finally, this journey reinforced that observability is critical. Without clear logs, metrics, and dashboards, it would have been nearly impossible to pinpoint the root cause or verify the effectiveness of our fix. Our Grafana dashboards, error logs, and ClickHouse ingestion metrics made it clear when the issue appeared, how severe it was, and how things stabilized after deploying the pooled solution. Good observability turned what could have been a long debugging marathon into a structured diagnosis and validation process.
Closing Thoughts
This issue was a great reminder that even high-level async code hides some deep concurrency challenges underneath.
The evolution - from a single shared client, to per-request isolation, to an efficient async connection pool - illustrates how understanding the runtime model (Uvicorn + async I/O) is just as important as writing correct business logic.